(2023-01-30) Wardley Why The Fuss About Conversational Programming
Simon Wardley: Why the fuss about conversational programming? *It’s not widely talked about yet, but it will be. To understand why, I’m going to build on my previous HackerNoon post on "Why the fuss about serverless?"
I called that practice FinDev in 2016. In the end we finally got a moniker of FinOps (2018) and subsequently a foundation, a book (O’Reilly Cloud FinOps) and several conferences built around those concepts of visibility into financial value and gluing together component services.
One of the questions that I was asked back in 2016 was “What comes after serverless”? I responded “Conversational programming”.
let us draw a map of the existing landscape. (wardley map)
In the map above, a user has some need which is normally met by an application running on a device.
number of components are shown as squares. These represent a pipeline of choice
Pipelines are used in maps when we have mutliple things with a common meaning e.g. “power” can mean renewable or fossil fuel or nuclear — they are all sources of “power”.
To explain this more clearly, let us expand out the map to discuss the serverless space.
In the map above, I’ve expanded out a number of the pipelines. For example, in compute we had the choice to use servers or cloud circa 2006 and onwards
To be clear, good practice for compute as a utility is called DevOps whilst “best” practice for compute as a product (aka servers) is these days called Legacy.
Given we’re already discussing discrete components in the pipelines, we can simply remove the surrounding pipelines. This gives us figure 3
Figure 3 — Serverless Map, 2023.
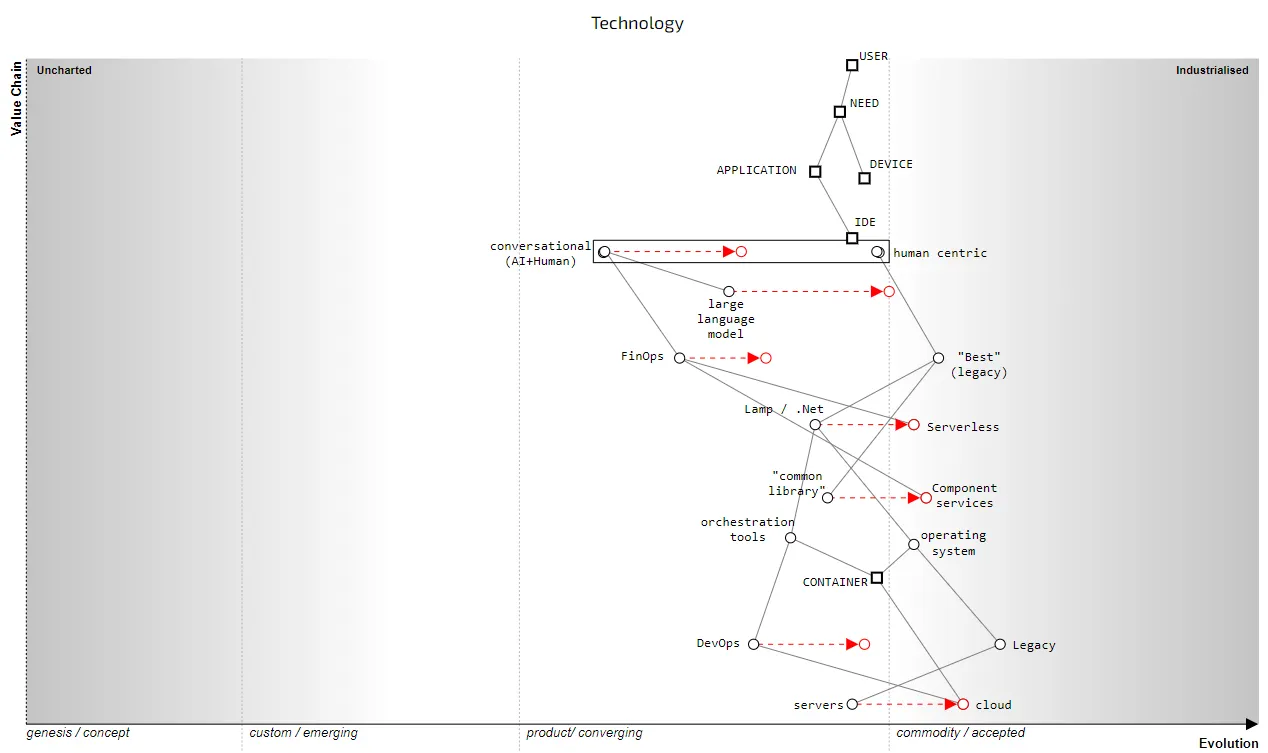
Common libraries are evolving to more component services in the FinOps world of serverless whereas best coding practice for use of LAMP/ .Net is built upon the concept of common libraries
WHAT IS CONVERSATIONAL PROGRAMMING?
Even in this serverless world, the act of programming still requires you to think about what component services need to be glued together. That means you have to break down the problem into components, find component services that match, determine what is missing and hence what you will need to build, then build it and glue it all together.
Figure 4 — Conversational Programming, 2023
The question you should be asking is whether the system can build or suggest things that it has never seen or been exposed to before?
If you prompt ChatGPT to write the control system for a sendor in a future teleportation system … it’ll write something like
With an awful lot of caveats about how it’ll need “modification, integration with other components, the code only demonstrates how to create an entangled pair of qubits in a local simulation but in a real teleportation system then the quantum channel would likely be implemented using specialized hardware and creating a complete teleportation system would require significant modifications and additional components beyond the simple sender’s control system code provided earlier”.
it lacks the data to provide a statistically accurate enough result. To do so will require discovery which is why the human + AI element will be so important
At this point we get to the “perhaps” and “statistical” bits. Our stochastic parrot isn’t some sort of linear analysis of text but a model trained on text
What if there are hidden meta strategies for innovation in the training data set that an AI can learn? Perhaps it could learn those?
The current state of conversational programming is prompt engineering.
It’s only a matter of time before OpenAI (ChatGPT) is tightly coupled into Azure’s development environment and programming will start to look more like a conversation between an engineer with an AI
One thing you might note in the map is how I’ve linked FinOps to conversational programming. Serverless has brought remarkable changes such as refactoring having financial value to the focus on financial visibility within code (including carbon cost of code) and these are unlikely to be lost in a conversational programming world
I hold a view that the discovery, interrogation and integration at the functional level will be a key part of this (as per the Aleksandar Simovic example). It’s why I’m not willing to bet on ChatGPT yet. I suspect the abstraction layer and fundamental model is slightly off target
This is a huge strategic advantage which in the past AWS has thoroughly enjoyed and made use of (see Reaching Cloud Velocity) and it’s at the heart of the ILC model (described in that book). Which is why I can’t see AWS doing an IBM and letting Microsoft walk away with this show.
SO WHEN WILL THIS HAPPEN?
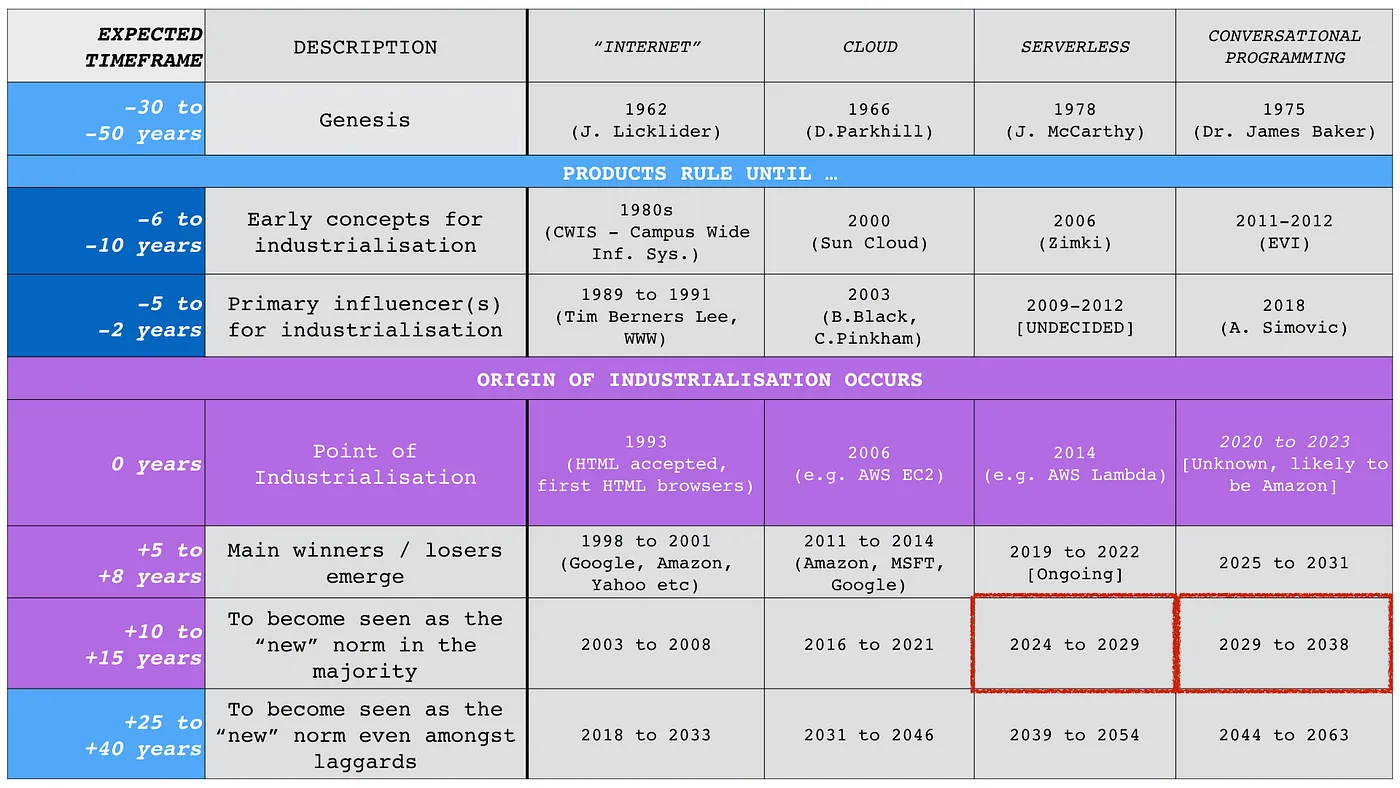
Back in 2019, I put together a rough timeline for when this would all start to kick off, see figure 5. I put a stake in the ground around 2020 to 2023
I would say we’re not there yet, we’re still in the “Sun Cloud” phase i.e. almost there but not quite.
Figure 5 — Timeline, 2019.
There will also be the usual nonsense peddled by large management consultants. It’s probably worth listing these :-
1) You’ll need less engineers
2) It’ll reduce IT budgets.
3) You have choice
4) It’s only for startups
5) We can build our own.
6) I can make a more efficient application by hand crafting the code
7) It’ll be the death of DevOps / FinOps etc
A NOTE ON PLATFORM ENGINEERING
Unfortunately, the term platform engineering seems to have got wrapped up with the idea of building your own platform. This is downright harmful if there are utility providers out there
As a rule of thumb, if you’re not currently a hyperscaler then your platform engineering team should be spending most of its effort in getting rid of things from your organisation and building instrumentation for this.
WHAT COMES NEXT?
SUMMARY
What any conversational system should be doing is watching as you write code and interrupting with a polite “excuse me, you don’t need to build that … just use this”.
If you take an application and start with the user needs and then map out the components required then you will find that the majority of the components have been built somewhere else. As a rule of thumb, around 95% of the code we need to build has already been written.
Edited: | Tweet this! | Search Twitter for discussion
No Space passed/matched! - http://www.wikiflux.net/wiki/2023-01-30-WardleyWhyTheFussAboutConversationalProgramming... Click here for WikiGraphBrowser
No Space passed/matched! - http://www.wikiflux.net/wiki/2023-01-30-WardleyWhyTheFussAboutConversationalProgramming

 Made with flux.garden
Made with flux.garden